

Since, p(xi, ηj) = p(xi) p(ηj) ≠ 0
Most functions are information lossy
For the system with minimal specifications

This can be shown in directed graph as

But we know that p(Y) = transitional probability × p(X).
Thus,

|

Therefore,
Given symbol xi we know about yk
Also
Given symbol yk we know about ηj
Thus p(yk|xi) = p(ηj|xi + ηj = yk ).
Hence we compute the mutual information between X and Y following the addition of N as follows

|
"Entropy of outcome of a function is not necessarily the same as entropy of the compound symbol".
This explains why in the above example system
or
H(Y) < H(X; N)
but never
H(Y) ≥ H(C)
"Most functions are information lossy".
❶Identifying confounding causes for information loss and solution to improve SNR (signal-to-noise ratio)
In our example the statement "Most functions are information lossy". applies because
How can this confounding of input be minimized?
One solution is
Normalization to improve SNR (signal–to–noise ratio).
In our example
p(N) = {0.1, 0.8, 0.1}

|

whose directed graph is
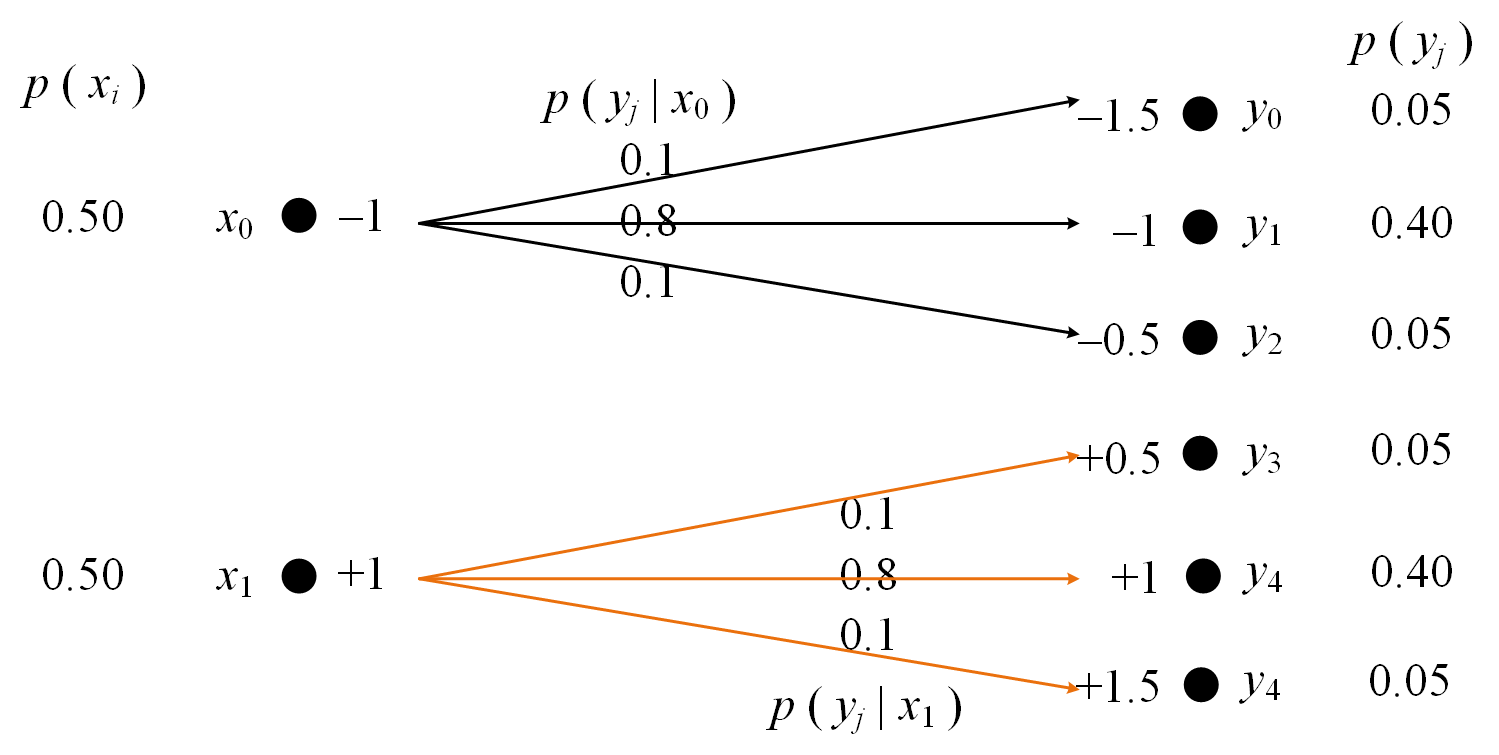
Therefore we have

Notice that H(X, N) = H(Y). This is because

|
Therefore information loss from the original symbol X after the output Y is given by
❷
Next:
Information in terms of usability (useful/useless) (p:2) ➽
