
Let us consider channels with memory. In other words channels that are statistically independent, p(x)p(y) ≠ 0. For example assume a DMS (discrete memoryless source X = {−1, +1}) sending symbols to a delay (D) such that their sum is the output,
| x at t = n − 1 |
x at t = n | |
|---|---|---|
| −1 | +1 | |
| −1 | −2 | 0 |
| +1 | 0 | +2 |


❶
Hidden Markov Process
If DMS and the duo–binary channel is considered an information source

then the Markov process that exist within this information source is called Hidden Markov Process.
In steady–state, analysis of the system shows that

|
(Note that the notation in the equation is x(n) = x(n). See above figure for the parametric values used for the above computations)
❷Drawing a state diagram
Let us say that the channel at time index n sends symbol xi where i ∈ {0, 1}. Let us also say that this channel has H(X) = 1. Thus p(x0) = p(x1) = 0.5.
At any time index n if the symbol is xi = −1 (i.e, xi = x0) let us define the 'state' as S = S0. On the other hand, if the symbol is xi = +1 (i.e, xi = x1) let us say its state is S = S1. Then the Markov–Process state diagram is

The diagram shows that if at state S0, for output y = −2 the symbol for next time index n is xi = x0. Since it is a statistically independent system
 . Thus the arrow is directed back to the same state. On the other hand, for output
. Thus the arrow is directed back to the same state. On the other hand, for output  (assuming that the initial state is S0) the next symbol must be xi = x1. Hence
(assuming that the initial state is S0) the next symbol must be xi = x1. Hence 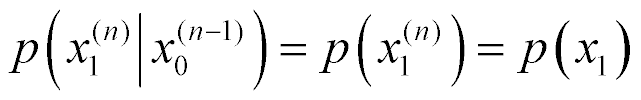 . The arrows is therefore directed from states S0 to S1. From the state-diagram one can make further analysis.
. The arrows is therefore directed from states S0 to S1. From the state-diagram one can make further analysis.
Let

|

|

|
![matrix 2 by 2 P = [p sub 00, p sub10; p sub 01, p sub11]](math/matrixP2by2.gif)
|
 . Since given a particular state, sum of all probabilities from this state must equal 1, p00 + p01 = p10 + p11 = 1.
❸
. Since given a particular state, sum of all probabilities from this state must equal 1, p00 + p01 = p10 + p11 = 1.
❸
Hence for the above example
![vector of length 2, mu at n+1 is equal to [0.5, 0.5; 0.5, 0.5] times [mu sub 0 at n; mu sub 1 at n]](math/vectormuatnplus1EgCompute.gif)
|
Continuing the analysis with the above example the state probability at steady-state (ss) is derived from the limit
![limit as n tends to infinity of vector mu at n is equal to steady-state vector of mu = [0.5; 0.5]](math/limitVectmuatnEqualsSSvectmuatn.gif)
|
